 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAMP: Training Explicit Memory for Mobile GUI Agents in Controllable and Scalable Virtual Environments
May 28, 2026Mobile GUI agents excel at immediate reactive control but frequently fail in realistic, long-horizon tasks that require memory. This failure stems from a fundamental conflict between limited context windows and token-heavy screenshots. To save the limited context, agents must progressively discard older visual history, permanently losing crucial transient information. Furthermore, existing action-centric datasets fail to teach agents what or when to explicitly memorize, and augmenting static real-world data is prohibitively expensive and lacks interactive verification. To resolve this, we present STAMP, a framework that trains explicit memory in mobile agents through controllable virtual environments, where deterministic memory variables are programmatically injected into synthesized tasks to control what must be memorized, when it should be encoded, and when it must later be retrieved, thereby producing verifiable supervised data at scale and enabling online reinforcement learning through environment-driven reward feedback. Evaluated on our newly introduced Memory-World benchmark, the resulting Stamp-GUI agent achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark, demonstrating exceptional memory accuracy and task resilience while maintaining strong general mobile navigation capabilities.
ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
May 12, 2026Computer Use Agents (CUAs) can act through both atomic GUI actions, such as click and type, and high-level tool calls, such as API-based file operations, but this hybrid action space often leaves them uncertain about when to continue with GUI actions or switch to tools, leading to suboptimal execution paths. This difficulty stems from the scarcity of high-quality interleaved GUI-Tool trajectories, the cost and brittleness of collecting real tool trajectories, and the lack of trajectory-level supervision for GUI-Tool path selection. In this paper, we propose ToolCUA, an end-to-end agent designed to learn optimal GUI-Tool path selection through a staged training paradigm. We first introduce an Interleaved GUI-Tool Trajectory Scaling Pipeline that repurposes abundant static GUI trajectories and synthesizes a grounded tool library, enabling diverse GUI-Tool trajectories without manual engineering or real tool-trajectory collection. We then perform Tool-Bootstrapped GUI RFT, combining warmup SFT with single-turn RL to improve decisions at critical GUI-Tool switching points. Finally, we optimize ToolCUA with Online Agentic RL in a high-fidelity GUI-Tool environment, guided by a Tool-Efficient Path Reward that encourages appropriate tool use and shorter execution paths. Experiments on OSWorld-MCP show that ToolCUA achieves 46.85% accuracy, a relative improvement of approximately 66% over the baseline, establishing a new state of the art among models of comparable scale. It also improves by 3.9% over GUI-only settings, demonstrating effective GUI-Tool orchestration. The results further suggest that training in a hybrid action space is a promising paradigm for real-world digital agents. Open-sourced here: https://x-plug.github.io/ToolCUA/
SemLayer: Semantic-aware Generative Segmentation and Layer Construction for Abstract Icons
Mar 25, 2026Graphic icons are a cornerstone of modern design workflows, yet they are often distributed as flattened single-path or compound-path graphics, where the original semantic layering is lost. This absence of semantic decomposition hinders downstream tasks such as editing, restyling, and animation. We formalize this problem as semantic layer construction for flattened vector art and introduce SemLayer, a visual generation empowered pipeline that restores editable layered structures. Given an abstract icon, SemLayer first generates a chromatically differentiated representation in which distinct semantic components become visually separable. To recover the complete geometry of each part, including occluded regions, we then perform a semantic completion step that reconstructs coherent object-level shapes. Finally, the recovered parts are assembled into a layered vector representation with inferred occlusion relationships. Extensive qualitative comparisons and quantitative evaluations demonstrate the effectiveness of SemLayer, enabling editing workflows previously inapplicable to flattened vector graphics and establishing semantic layer reconstruction as a practical and valuable task. Project page: https://xxuhaiyang.github.io/SemLayer/
CyCLeGen: Cycle-Consistent Layout Prediction and Image Generation in Vision Foundation Models
Mar 16, 2026We present CyCLeGen, a unified vision-language foundation model capable of both image understanding and image generation within a single autoregressive framework. Unlike existing vision models that depend on separate modules for perception and synthesis, CyCLeGen adopts a fully integrated architecture that enforces cycle-consistent learning through image->layout->image and layout->image->layout generation loops. This unified formulation introduces two key advantages: introspection, enabling the model to reason about its own generations, and data efficiency, allowing self-improvement via synthetic supervision under a reinforcement learning objective guided by cycle consistency. Extensive experiments show that CyCLeGen achieves significant gains across diverse image understanding and generation benchmarks, highlighting the potential of unified vision-language foundation models.
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Feb 15, 2026The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
AgentOCR: Reimagining Agent History via Optical Self-Compression
Jan 08, 2026Recent advances in large language models (LLMs) enable agentic systems trained with reinforcement learning (RL) over multi-turn interaction trajectories, but practical deployment is bottlenecked by rapidly growing textual histories that inflate token budgets and memory usage. We introduce AgentOCR, a framework that exploits the superior information density of visual tokens by representing the accumulated observation-action history as a compact rendered image. To make multi-turn rollouts scalable, AgentOCR proposes segment optical caching. By decomposing history into hashable segments and maintaining a visual cache, this mechanism eliminates redundant re-rendering. Beyond fixed rendering, AgentOCR introduces agentic self-compression, where the agent actively emits a compression rate and is trained with compression-aware reward to adaptively balance task success and token efficiency. We conduct extensive experiments on challenging agentic benchmarks, ALFWorld and search-based QA. Remarkably, results demonstrate that AgentOCR preserves over 95\% of text-based agent performance while substantially reducing token consumption (>50\%), yielding consistent token and memory efficiency. Our further analysis validates a 20x rendering speedup from segment optical caching and the effective strategic balancing of self-compression.
CVP: Central-Peripheral Vision-Inspired Multimodal Model for Spatial Reasoning
Dec 09, 2025We present a central-peripheral vision-inspired framework (CVP), a simple yet effective multimodal model for spatial reasoning that draws inspiration from the two types of human visual fields -- central vision and peripheral vision. Existing approaches primarily rely on unstructured representations, such as point clouds, voxels, or patch features, and inject scene context implicitly via coordinate embeddings. However, this often results in limited spatial reasoning capabilities due to the lack of explicit, high-level structural understanding. To address this limitation, we introduce two complementary components into a Large Multimodal Model-based architecture: target-affinity token, analogous to central vision, that guides the model's attention toward query-relevant objects; and allocentric grid, akin to peripheral vision, that captures global scene context and spatial arrangements. These components work in tandem to enable structured, context-aware understanding of complex 3D environments. Experiments show that CVP achieves state-of-the-art performance across a range of 3D scene understanding benchmarks.
MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
Nov 16, 2025Document parsing is a core task in document intelligence, supporting applications such as information extraction, retrieval-augmented generation, and automated document analysis. However, real-world documents often feature complex layouts with multi-level tables, embedded images or formulas, and cross-page structures, which remain challenging for existing OCR systems. We introduce MonkeyOCR v1.5, a unified vision-language framework that enhances both layout understanding and content recognition through a two-stage pipeline. The first stage employs a large multimodal model to jointly predict layout and reading order, leveraging visual information to ensure sequential consistency. The second stage performs localized recognition of text, formulas, and tables within detected regions, maintaining high visual fidelity while reducing error propagation. To address complex table structures, we propose a visual consistency-based reinforcement learning scheme that evaluates recognition quality via render-and-compare alignment, improving structural accuracy without manual annotations. Additionally, two specialized modules, Image-Decoupled Table Parsing and Type-Guided Table Merging, are introduced to enable reliable parsing of tables containing embedded images and reconstruction of tables crossing pages or columns. Comprehensive experiments on OmniDocBench v1.5 demonstrate that MonkeyOCR v1.5 achieves state-of-the-art performance, outperforming PPOCR-VL and MinerU 2.5 while showing exceptional robustness in visually complex document scenarios. A trial link can be found at https://github.com/Yuliang-Liu/MonkeyOCR .
Efficient and Effective In-context Demonstration Selection with Coreset
Nov 12, 2025In-context learning (ICL) has emerged as a powerful paradigm for Large Visual Language Models (LVLMs), enabling them to leverage a few examples directly from input contexts. However, the effectiveness of this approach is heavily reliant on the selection of demonstrations, a process that is NP-hard. Traditional strategies, including random, similarity-based sampling and infoscore-based sampling, often lead to inefficiencies or suboptimal performance, struggling to balance both efficiency and effectiveness in demonstration selection. In this paper, we propose a novel demonstration selection framework named Coreset-based Dual Retrieval (CoDR). We show that samples within a diverse subset achieve a higher expected mutual information. To implement this, we introduce a cluster-pruning method to construct a diverse coreset that aligns more effectively with the query while maintaining diversity. Additionally, we develop a dual retrieval mechanism that enhances the selection process by achieving global demonstration selection while preserving efficiency. Experimental results demonstrate that our method significantly improves the ICL performance compared to the existing strategies, providing a robust solution for effective and efficient demonstration selection.
Learning Filter-Aware Distance Metrics for Nearest Neighbor Search with Multiple Filters
Nov 06, 2025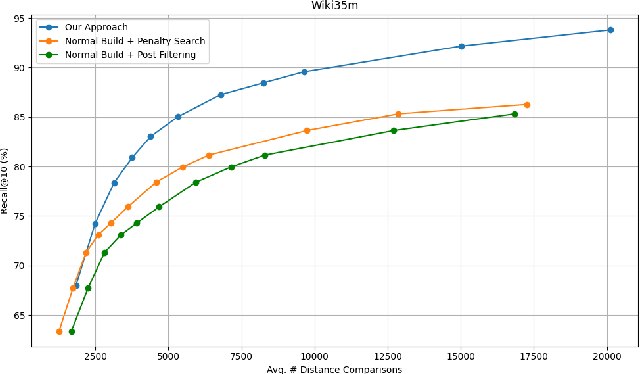
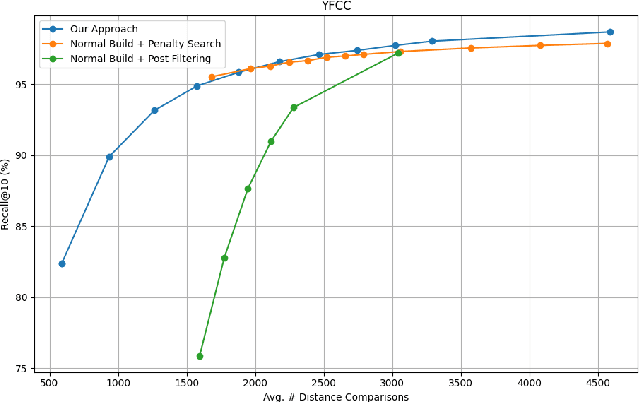
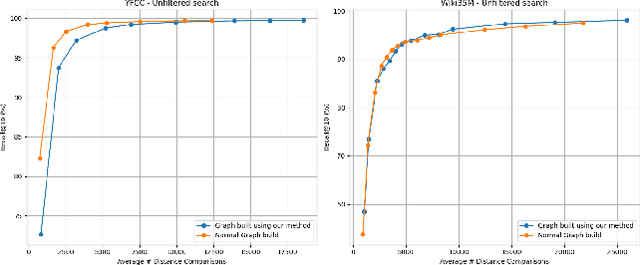
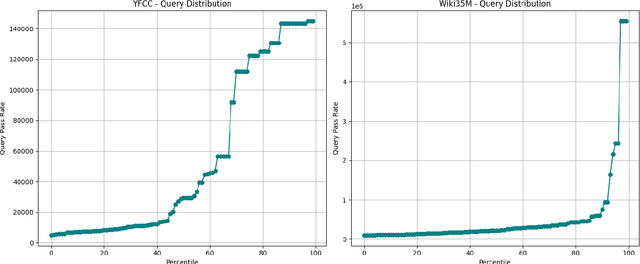
Filtered Approximate Nearest Neighbor (ANN) search retrieves the closest vectors for a query vector from a dataset. It enforces that a specified set of discrete labels $S$ for the query must be included in the labels of each retrieved vector. Existing graph-based methods typically incorporate filter awareness by assigning fixed penalties or prioritizing nodes based on filter satisfaction. However, since these methods use fixed, data in- dependent penalties, they often fail to generalize across datasets with diverse label and vector distributions. In this work, we propose a principled alternative that learns the optimal trade-off between vector distance and filter match directly from the data, rather than relying on fixed penalties. We formulate this as a constrained linear optimization problem, deriving weights that better reflect the underlying filter distribution and more effectively address the filtered ANN search problem. These learned weights guide both the search process and index construction, leading to graph structures that more effectively capture the underlying filter distribution and filter semantics. Our experiments demonstrate that adapting the distance function to the data significantly im- proves accuracy by 5-10% over fixed-penalty methods, providing a more flexible and generalizable framework for the filtered ANN search problem.